862. Shortest Subarray with Sum at Least K
내 코드
그냥 투포인터(슬라이딩 윈도우) 아닌가? 했다가 실패.
- 마지막 값이 음수인 경우 값이 늘어나는데, 그러면 범위를 줄일 수 있다. (지금의 경우 값이 양수인 경우에만 성립할 듯 하다..)
class Solution {
public:
int shortestSubarray(vector<int>& nums, int k) {
long long sum{};
int s{}, e{}; // [e, s]
int answer = 1 << 30;
for (int s{}; s < nums.size(); ++s) {
sum += nums[s];
if (sum >= k) {
answer = min(answer, s - e + 1);
}
while (sum >= k && e < s) {
sum -= nums[e];
answer = min(answer, s - e + 1);
++e;
}
}
if (answer == 1 << 30) answer = -1;
return answer;
}
};Solution
Overview
유사한 문제: 209. Minimum Size Subarray Sum
다른 점: 숫자에 음수가 있어 기존의 sliding window로는 풀 수 없음.
Approach 1: Priority Queue
brute force 너무 느리다.
같은 subarray의 sum을 여러 번 계산해야 하는 문제. prefixSum Array를 미리 게산.
그러나 여전히 best prefix sum을 찾는 것이 여전히 느리다. heap이 유용하게 도움을 줄 수 있음.
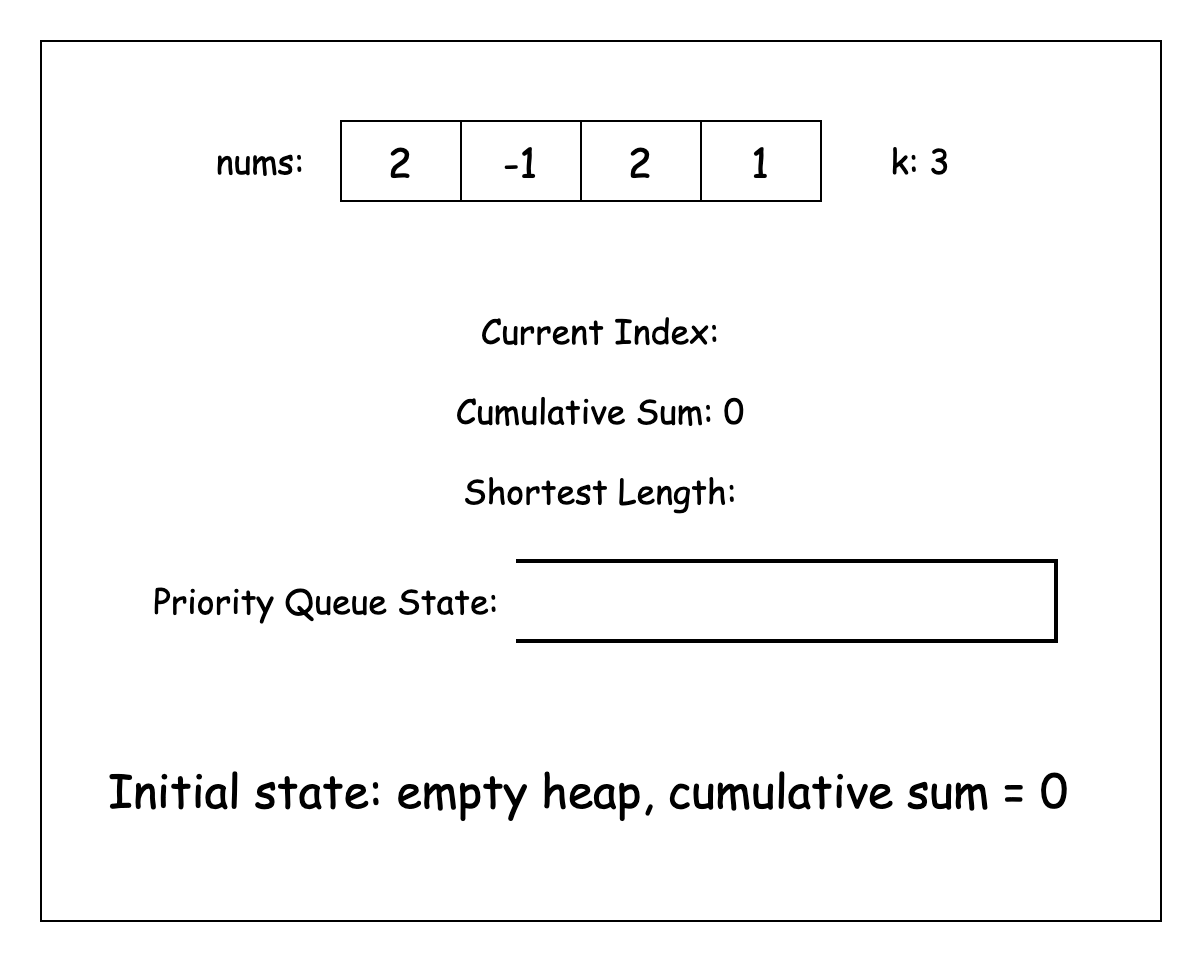
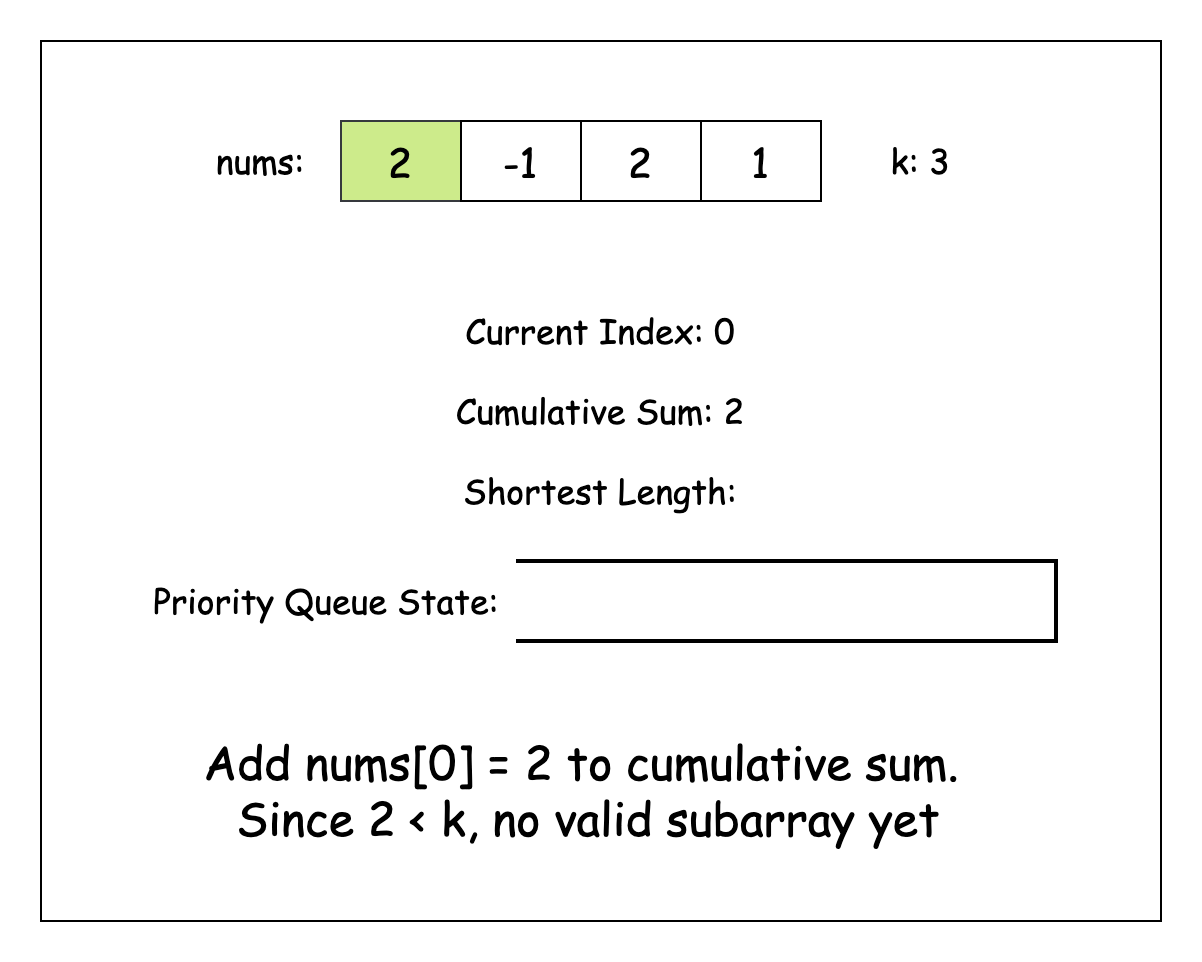
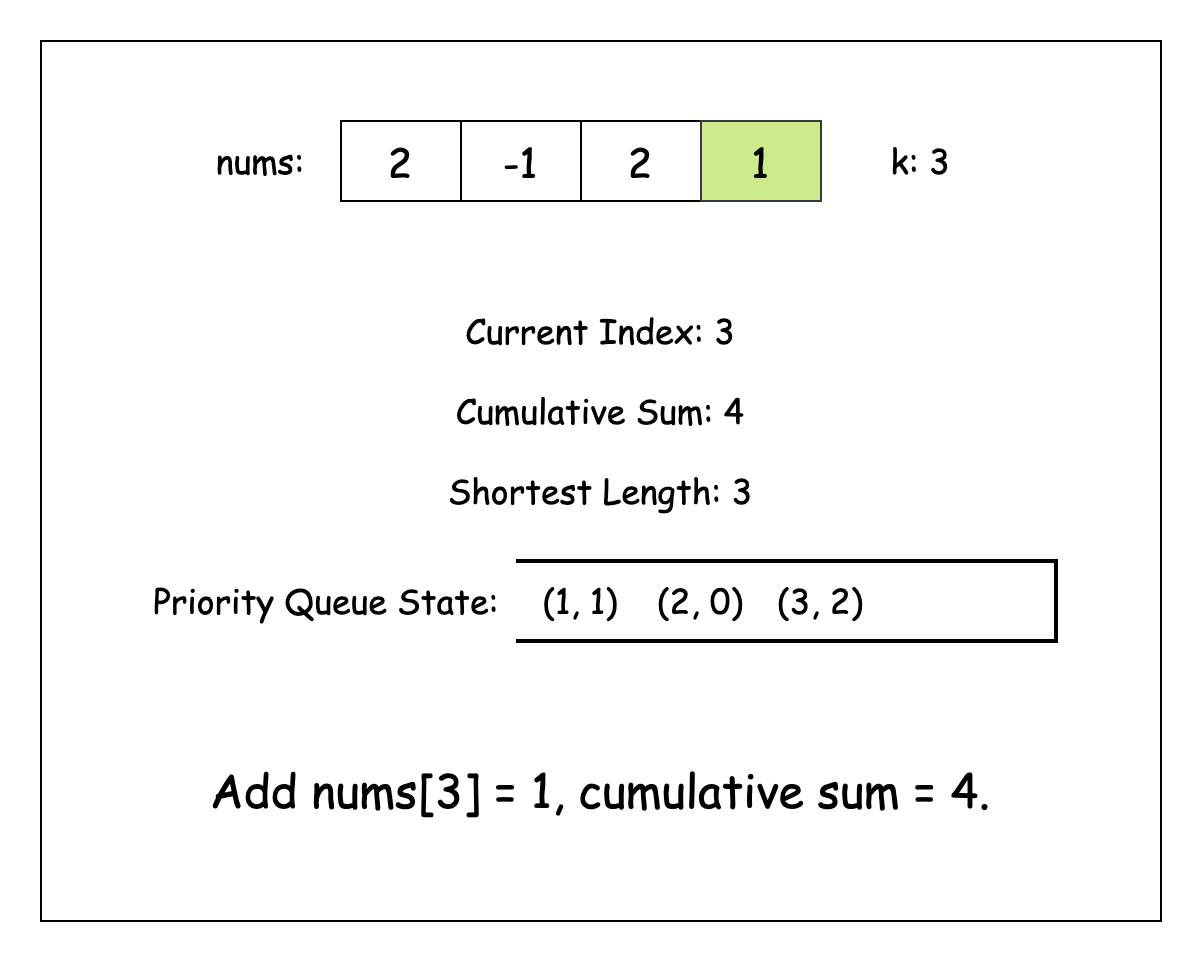
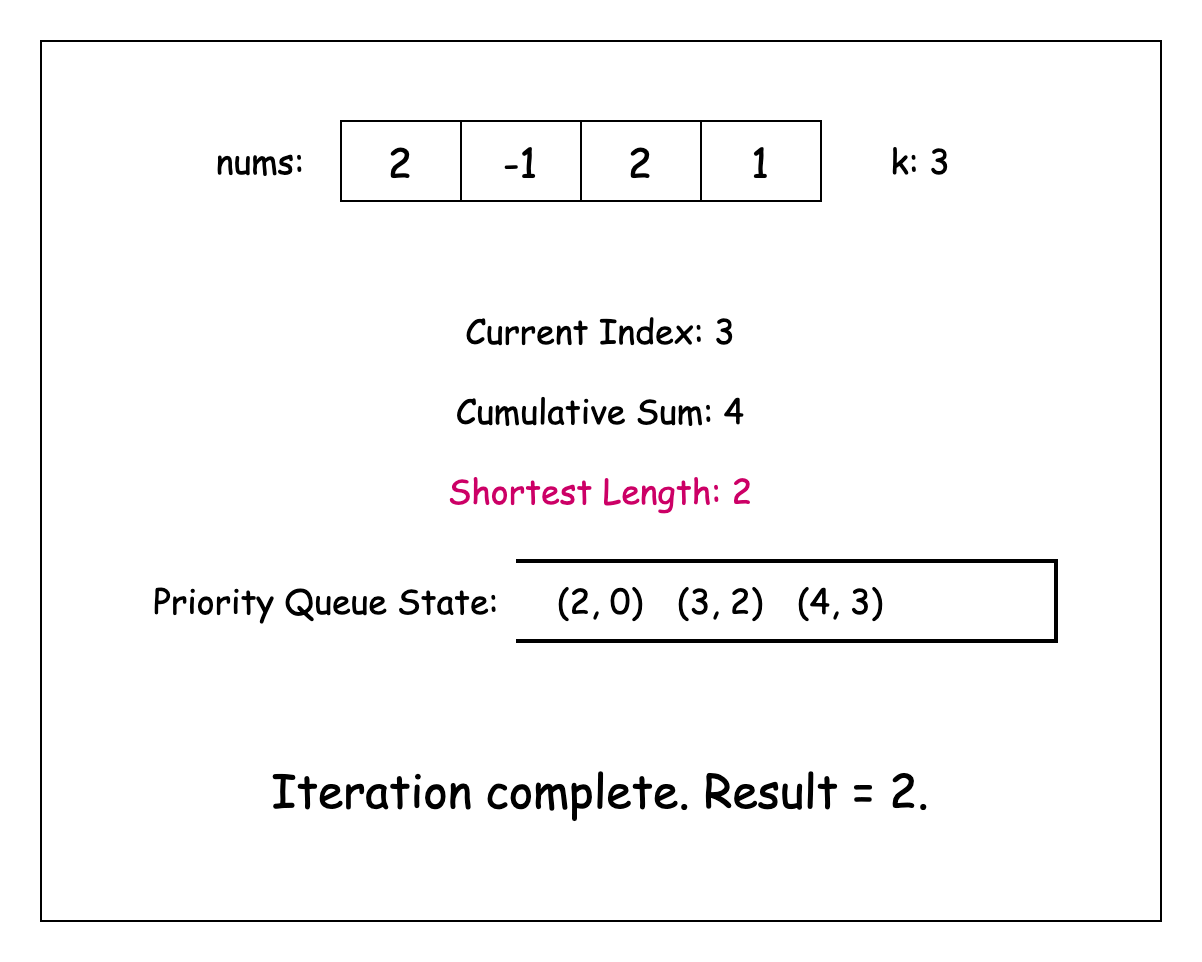
이제 nums 배열을 반복하면서, 누적 합을 cumulativeSum이라는 변수에 저장하자. 동시에 결과값을 저장할 변수인 shortestSubarrayLength도 관리하자.
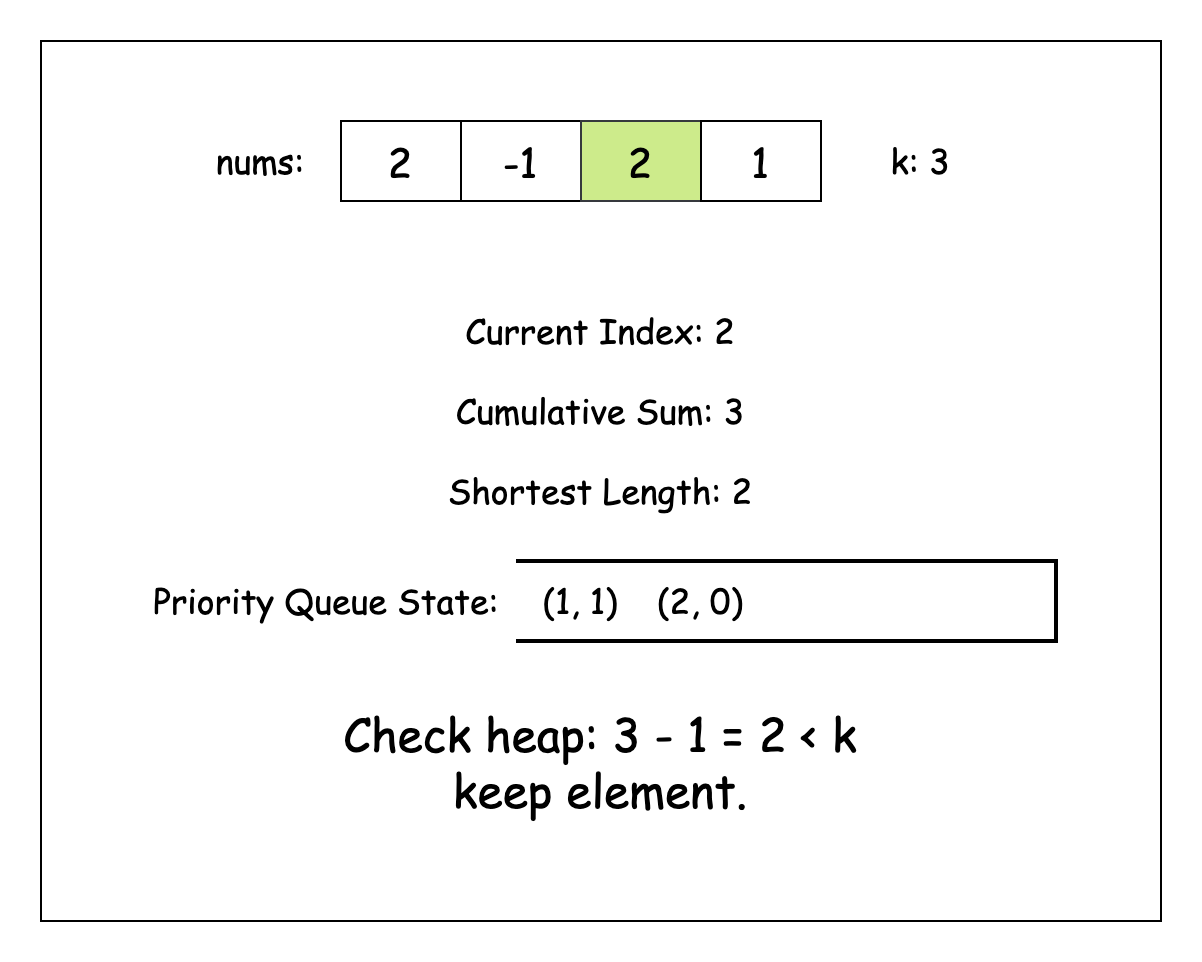
cumulativeSum이 조건을 충족하면 이를 잠재적인 결과로 간주하자. 그렇지 않을 경우, 힙의 최상단 요소와의 차이가 k 이상일 동안 힙의 최상단 요소를 반복적으로 확인하자.
각 요소를 확인할 때, 지금까지 발견한 최소 길이의 부분 배열인지 확인하자. 힙의 요소를 확인한 후에는 이를 버릴 수 있는데, 반복문에서 이후에 나올 모든 합은 더 긴 부분 배열을 만들게 되어 답이 될 수 없기 때문임.
유효한 이전의 접두사 합(prefix sum)을 모두 확인한 후에는 현재 합과 해당 인덱스를 힙에 추가할 수 있음.








- 87ms, 119.78MB
- Complexity
- Let be the length of the
numsarray. - Time Complexity:
- Space Complexity:
- Let be the length of the
class Solution {
public:
int shortestSubarray(vector<int>& nums, int k) {
int n = nums.size();
// Initialize result to the maximum possible integer value
int shortestSubarrayLength = INT_MAX;
long long cumulativeSum = 0;
// Min-heap to store cumulative sum and its corresponding index
priority_queue<pair<long long, int>, vector<pair<long long, int>>,
greater<>>
prefixSumHeap;
// Iterate through the array
for (int i = 0; i < n; i++) {
// Update cumulative sum
cumulativeSum += nums[i];
// If cumulative sum is already >= k, update shortest length
if (cumulativeSum >= k) {
shortestSubarrayLength = min(shortestSubarrayLength, i + 1);
}
// Remove subarrays from heap that can form a valid subarray
while (!prefixSumHeap.empty() &&
cumulativeSum - prefixSumHeap.top().first >= k) {
// Update shortest subarray length
shortestSubarrayLength =
min(shortestSubarrayLength, i - prefixSumHeap.top().second);
prefixSumHeap.pop();
}
// Add current cumulative sum and index to heap
prefixSumHeap.emplace(cumulativeSum, i);
}
// Return -1 if no valid subarray found
return shortestSubarrayLength == INT_MAX ? -1 : shortestSubarrayLength;
}
};Approach 2: Monotonic Stack + Binary Search
priority queue binary search
nums 배열을 순회하면서 각 인덱스의 접두사 합(prefix sum)을 저장하기 위해 스택과 유사한 데이터 구조를 사용합니다.
스택의 각 요소는 [접두사 합, 인덱스] 쌍으로 저장되며, 접두사 합이 단조 증가하도록 유지합니다.
이를 구현하기 위해, 배열의 각 숫자에 대해 실행 중인 총합(running total)을 업데이트하면서 시작합니다.
그런 다음, 현재 합보다 크거나 같은 항목은 스택의 맨 위에서 제거하여 구조가 정렬되도록 유지합니다. 이 방법은 접두사 합과 해당 인덱스가 엄격히 증가하는 순서를 유지하도록 보장합니다.
이 순서가 유지되면 이진 검색을 사용해 current_sum - k 이상인 가장 오른쪽 항목을 효율적으로 찾을 수 있습니다.
현재 위치와 찾은 인덱스 간의 차이는 유효한 부분 배열의 길이를 나타냅니다. 우리가 찾는 가장 짧은 길이를 추적함으로써 최종 답을 얻을 수 있습니다.
- 44ms, 110.34MB
- Complexity
- Let be the length of the
numsarray. - Time Complexity:
- Space Complexity:
- Let be the length of the
class Solution {
public:
int shortestSubarray(vector<int>& nums, int k) {
int n = nums.size();
// Stack-like list to store cumulative sums and their indices
vector<pair<long long, int>> cumulativeSumStack;
cumulativeSumStack.emplace_back(0LL, -1);
long long runningCumulativeSum = 0;
int shortestSubarrayLength = INT_MAX;
for (int i = 0; i < n; i++) {
// Update cumulative sum
runningCumulativeSum += nums[i];
// Remove entries from stack that are larger than current cumulative
// sum
while (!cumulativeSumStack.empty() &&
runningCumulativeSum <= cumulativeSumStack.back().first) {
cumulativeSumStack.pop_back();
}
// Add current cumulative sum and index to stack
cumulativeSumStack.emplace_back(runningCumulativeSum, i);
int candidateIndex = findCandidateIndex(cumulativeSumStack,
runningCumulativeSum - k);
// If a valid candidate is found, update the shortest subarray
// length
if (candidateIndex != -1) {
shortestSubarrayLength =
min(shortestSubarrayLength,
i - cumulativeSumStack[candidateIndex].second);
}
}
// Return -1 if no valid subarray found
return shortestSubarrayLength == INT_MAX ? -1 : shortestSubarrayLength;
}
private:
// Binary search to find the largest index where cumulative sum is <= target
int findCandidateIndex(const vector<pair<long long, int>>& nums,
long long target) {
int left = 0, right = nums.size() - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid].first <= target) {
left = mid + 1;
} else {
right = mid - 1;
}
}
return right;
}
};Approach 3: Deque
challenge: find both the smallest sum and the largest index before our current position.
답은 deque(이중 연결 큐) 를 사용하는 것에 있습니다. Deque는 양쪽 끝에서 항목을 추가하거나 제거할 수 있어 우리의 필요에 완벽히 맞는 자료 구조입니다.
이 경우, deque는 목표 부분 배열의 시작점이 될 수 있는 접두사 합(prefix sum)의 인덱스를 저장하게 됩니다. 또한, 이러한 합이 단조 증가하는 순서를 유지하도록 합니다. 이 단조성(monotonicity)은 매우 중요한데, 이후의 접두사 합보다 크거나 같은 이전 접두사 합이 발견되면, 이후의 인덱스는 항상 더 짧은 부분 배열을 제공하며, 동일하거나 더 큰 합을 가질 가능성이 있기 때문입니다.
각 위치를 순회하면서 먼저 deque에 저장된 인덱스를 사용해 유효한 부분 배열을 찾을 수 있는지 확인합니다. 이를 위해 현재 접두사 합과 deque의 앞부분에 저장된 접두사 합 간의 차이를 계산합니다. 이 차이가 목표 합에 도달하거나 초과하면, 유효한 부분 배열을 찾은 것입니다. 이 경우, shortestSubarrayLength를 업데이트하고, deque의 앞부분에 저장된 해당 시작 인덱스를 제거합니다. 이는 이후의 끝 위치에서는 더 짧은 부분 배열을 찾는 데 도움이 되지 않기 때문입니다.
그 다음으로, deque의 단조성을 유지해야 합니다. deque의 뒷부분에 저장된 인덱스의 접두사 합이 현재 접두사 합보다 크거나 같다면, 해당 인덱스를 deque에서 제거합니다. 이 단계는 매우 중요한데, 제거된 위치는 동일하거나 더 작은 합을 가지며 더 긴 부분 배열만을 제공할 것이기 때문에, 우리의 목적에는 불필요합니다.
마지막으로, 현재 인덱스를 deque의 뒤쪽에 추가합니다. 이는 해당 인덱스가 이후에 유효한 부분 배열의 시작점이 될 가능성이 있기 때문입니다.
배열을 모두 순회한 후에는, shortestSubarrayLength 변수에 우리가 찾는 조건을 만족하는 가장 짧은 부분 배열의 길이가 저장되어 있습니다.
- 25ms, 107.63MB
- Complexity
- Let be the length of the
numsarray. - Time Complexity:
- Space Complexity:
- Let be the length of the
class Solution {
public:
int shortestSubarray(vector<int>& nums, int targetSum) {
int n = nums.size();
// Size is n+1 to handle subarrays starting from index 0
vector<long long> prefixSums(n + 1, 0);
// Calculate prefix sums
for (int i = 1; i <= n; i++) {
prefixSums[i] = prefixSums[i - 1] + nums[i - 1];
}
deque<int> candidateIndices;
int shortestSubarrayLength = INT_MAX;
for (int i = 0; i <= n; i++) {
// Remove candidates from front of deque where subarray sum meets
// target
while (!candidateIndices.empty() &&
prefixSums[i] - prefixSums[candidateIndices.front()] >=
targetSum) {
// Update shortest subarray length
shortestSubarrayLength =
min(shortestSubarrayLength, i - candidateIndices.front());
candidateIndices.pop_front();
}
// Maintain monotonicity by removing indices with larger prefix sums
while (!candidateIndices.empty() &&
prefixSums[i] <= prefixSums[candidateIndices.back()]) {
candidateIndices.pop_back();
}
// Add current index to candidates
candidateIndices.push_back(i);
}
// Return -1 if no valid subarray found
return shortestSubarrayLength == INT_MAX ? -1 : shortestSubarrayLength;
}
};